近日,AI公司Graphcore的一支研究团队在Arxiv页面上公布了一项名为SparQ Attention的新技术。这项技术旨在降低大语言模型的内存带宽要求,从而提升模型的效率和性能。
研究团队表示,SparQ Attention技术通过选择性获取缓存历史记录来降低注意块内的内存带宽要求。这意味着在处理大语言模型时,该技术可以有效地减少模型对内存带宽的依赖,从而提高模型的运行速度和效率。
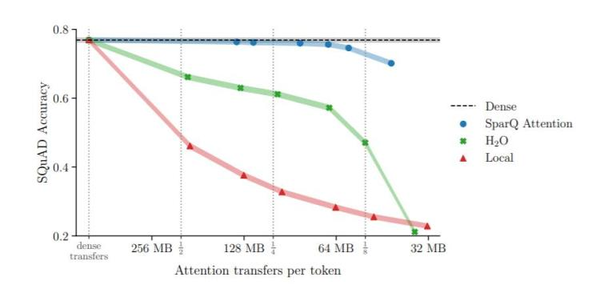

更重要的是,这项技术可以在推理过程中直接应用于现成的大语言模型,而无需修改预训练设置或进行额外的微调。这为现有的大语言模型提供了更高效、更灵活的解决方案,进一步推动了AI领域的发展。
研究团队还通过评估Llama 2和Pythia模型在各种下游任务中的表现来验证了SparQ Attention技术的有效性。结果显示,该技术可以将大模型的内存和带宽要求降低八倍,而准确率不会降低。这无疑证明了该技术的优势和潜力。Graphcore发布的SparQ Attention技术为AI领域带来了新的突破。通过降低大语言模型的内存带宽要求,该技术有望推动AI技术的进一步发展和应用。