近日,清华大学与华为研究团队联合发布了一项新技术,通过语义压缩技术,可以提高大模型文本输入的限制。这一技术的推出,为大模型在文本处理领域的应用提供了更广阔的空间。
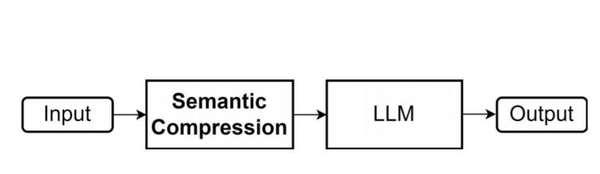
该技术从信息论中的源编码中汲取灵感,采用预先训练好的模型来减少长输入的语义冗余,然后再将其传递给LLM执行下游任务。这一过程不仅提高了文本输入的长度,而且不需要大量的计算成本,也不需要进行微调。
实验结果表明,该方法有效地扩展了大语言模型的上下文窗口,并适用于一系列任务,包括问题解答、总结、少量学习和信息检索等。这一技术的推出,将有助于提升大模型在文本处理领域的性能和效率。
华为与清华大学的这一合作,展示了在AI技术领域的跨界合作与创新的可能性。两家公司各自拥有强大的技术实力和研发能力,通过联合研究,能够相互借鉴、共同推动技术的发展。

随着AI技术的不断发展,大模型在文本处理领域的应用越来越广泛。然而,大模型的文本输入限制一直是限制其性能提升的一个瓶颈。清华与华为的这项新技术,为大模型的文本输入提供了更广阔的空间,有望推动AI技术在文本处理领域的进一步发展。
清华与华为的这项新技术为大模型的文本输入提供了新的解决方案,将有助于提升AI技术在文本处理领域的性能和效率。我们期待这一技术在未来的发展中能够带来更多的创新和应用。