在人工智能领域,大模型已经成为了许多应用的基石。然而,随着其应用的广泛,大模型的幻觉问题也日益凸显。近日,同济大学与复旦大学的研究团队联手,发布了一种名为“检索增强生成(RAG)”的新方法,旨在解决这一挑战。
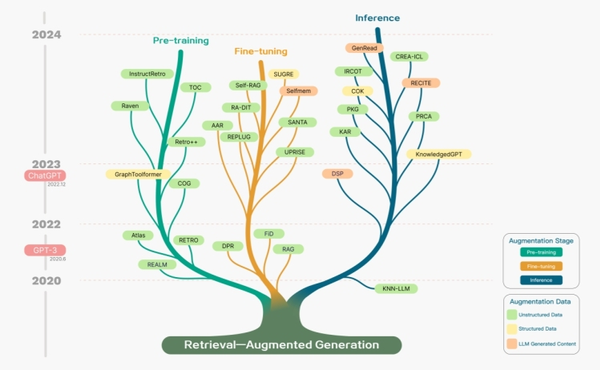

RAG的核心理念是在回答问题之前,从外部知识库中检索相关信息,以增强答案的准确性并减少模型的幻觉。这一方法尤其适用于知识密集型任务,通过引用来源,用户可以验证答案的准确性,增加对模型输出的信任。
这一研究的发布,无疑为解决大模型幻觉问题提供了新的思路。RAG不仅提高了答案的准确性,减少了模型的幻觉,还促进了知识的更新和特定领域知识的引入。这对于大模型在各个领域的应用都具有重要的意义。
大模型的幻觉问题长期以来一直是业界关注的焦点。传统的解决方法往往侧重于优化模型的内部结构或调整训练方法。然而,RAG提供了一个全新的视角,即通过外部知识库的检索来提高答案的准确性。这一方法为大模型的应用开辟了新的可能性和空间。
值得注意的是,RAG的应用并不局限于特定的领域。无论是自然语言处理、智能问答、还是更广泛的知识推理任务,RAG都展现出了其独特的优势。这使得RAG具有广泛的应用前景,未来有望在各个领域中得到广泛应用。
同济大学与复旦大学的这一合作研究为我们解决大模型幻觉问题提供了一个有力的工具。我们期待RAG在未来的研究中能够进一步发展和完善,为大模型的应用和人工智能的发展注入新的活力。